INITRUNNER(1)USER COMMANDSv2026.6.9 · MIT
An init system for AI agents.
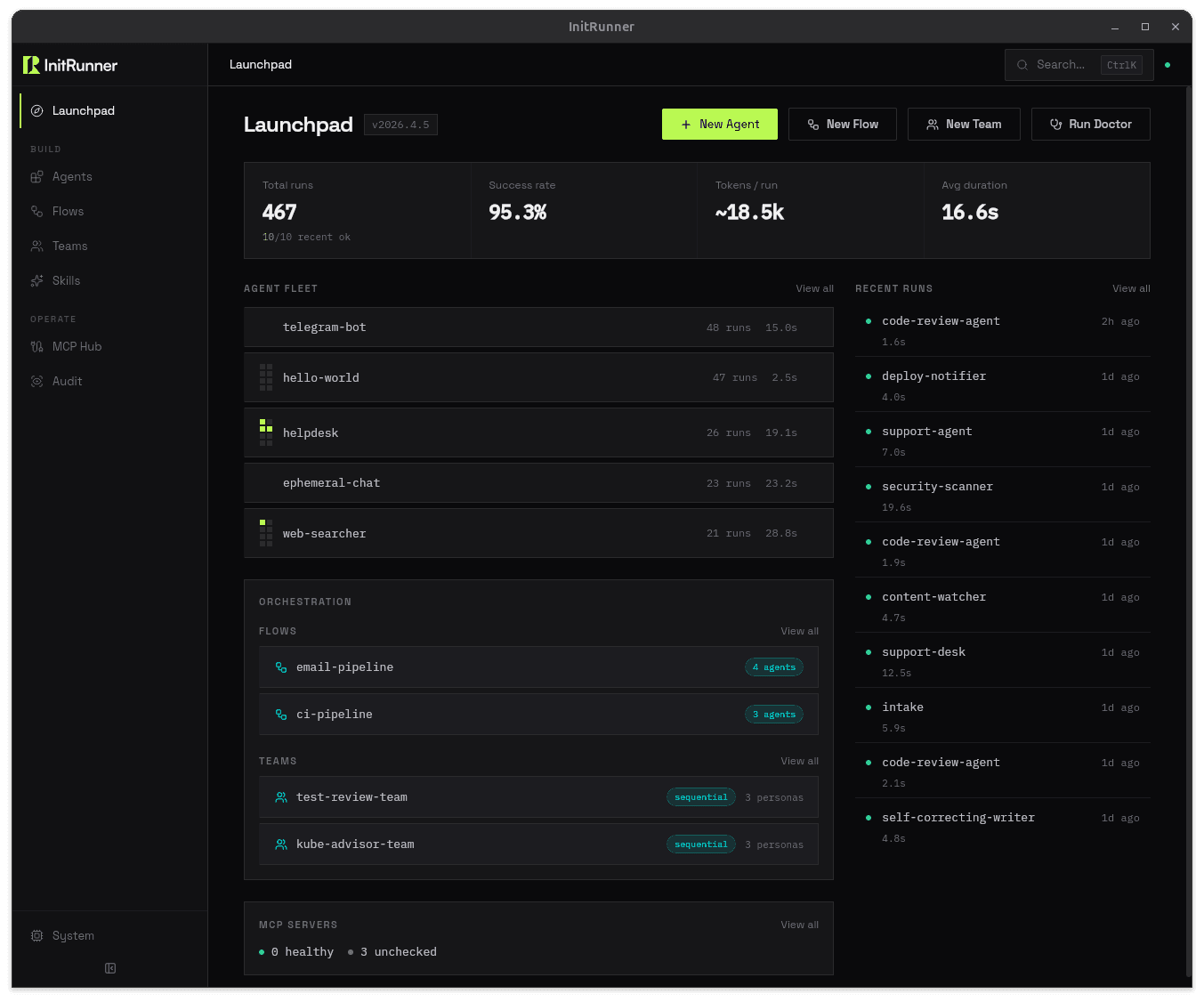
Define an agent as a YAML role file. Run it with one command. Your first agent is up in five minutes. Generate the file with initrunner new, pull one from InitHub, or import from PydanticAI or LangChain.
5,000+ tests · 28 tool types · 12+ providers · MIT licensed
curl -fsSL https://initrunner.ai/install.sh | shboot loginitrunner v2026.6.9
$ initrunner run agent.yaml [ OK ] Parsed role file agent.yaml[ OK ] Resolved provider anthropic[ OK ] Mounted tools: git, http, shell[ OK ] Restored memory (3 stores)[ OK ] Indexed ./docs for retrieval[ OK ] Opened append-only audit log[ OK ] Armed triggers: cron, webhook[ OK ] Reached target Agent Ready agent >